 SEM 广告营销
SEM 广告营销
 SEO 全站营销
SEO 全站营销
 B2B 品牌建站
B2B 品牌建站
 企业简介
企业简介
 企业文化
企业文化
 员工风采
员工风采
 企业环境
企业环境
 企业荣誉
企业荣誉
 领聚动态
领聚动态
 行业洞察
行业洞察
 联系方式
联系方式
 加入我们
加入我们

聊到谷歌蜘蛛爬行原理,大家可能会觉得比较复杂,今天这篇文章小编简单给大家文字说明下这里面的流程和逻辑,以及相关的运营优化人员在做网站内容时的对应注意事项。
爬行是搜索引擎工作的起点,也就是发现页面、发现新信息,然后才是将有价值的页面编入索引,进行排名。
Google 搜索也有自己非常明确的工作流程,主要分为 3个阶段,并非每个网页都会经历这 3 个阶段:
抓取:Google 会使用名为“抓取工具”的自动程序从互联网上发现各类网页,并下载其中的文本、图片和视频。
索引编制:Google 会分析网页上的文本、图片和视频文件,并将信息存储在大型数据库 Google 索引中。
呈现搜索结果:当用户在 Google 中搜索时,Google 会返回与用户查询相关的信息。
值得注意的是,之前提到过,爬虫初次来到网页时,抓取并解析的是网页的HTML代码,看到的页面类似于网页快照里的纯文字版本,而完整版本的页面需要后续经过渲染(rendering)才能被谷歌看到。
因此,我们要尽量避免把重要的内容(标题、描述、关键字等)放在Javascript中,否则搜索引擎爬虫可能无法正确抓取和理解这些内容。另外,如果你网页上某些链接需要执行Javascript才能被发现,那大概率这个链接不会被爬虫发现了。
简单来说,在网站网页的抓取过程中,蜘蛛有自己的抓取规则,一般情况下,网站内容主要由文本,视频,图片这三大部分的内容构成。谷歌会结合自己的规则重点优先抓取文本内容,也是我们重点说的文字内容,当然在现在的网站运营过程中,文字内容并非是指简单的参数或者表格方面的文字,而是相关的卖点优势或者企业产品价值相关的段落性的文字描述内容。
那么谷歌蜘蛛具体的工作流程和规则是怎样的,下面可以利用这张图来重点说明下:
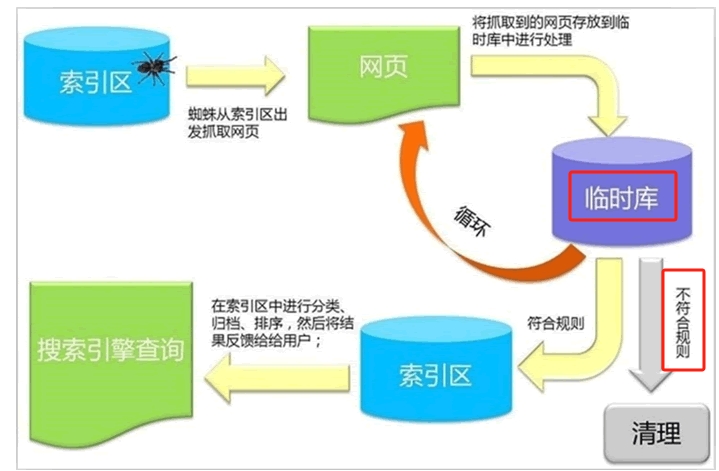
步骤一:蜘蛛在数据库或者索引区中等待,当网页发生变化或者有新增内容时,蜘蛛会从索引区中爬出并抓取网页;
步骤二:蜘蛛抓取到的所有网页,不会直接存储到谷歌数据库中,而是先被放到临时库里;
步骤三:这个步骤开始出现分流,被蜘蛛放到临时库中的网页或者内容,谷歌利用自己的算法和网页评分规则,将临时库中的网页分类,符合规则的进入下一步环节,不符合规则的页面,直接被蜘蛛清理掉;
在这里很多用户或者运营人员会有一个比较大的误区,那就是很多网页都会被收录到谷歌的数据库中,这一定不是绝对的,谷歌会最终结合自己的抓取规则和逻辑匹配页面的相关度和是否符合规则。
步骤四:蜘蛛对进入索引区的网页进行再次归类,并把最符合客户匹配度的页面展示给用户。
以上就是谷歌蜘蛛爬行和抓取原理以及对应的步骤流程,如果您有更多海外优化推广或者海外独立站优化推广方面的问题,欢迎随时咨询。